Simple Online Realtime Tracking
realtime object tracking 알고리즘. 그중에서도 Online Object Tracking을 다룬다.

Online OT의 경우 이전 프레임 혹은 전전프레임과 현재 프레임의 정보만 가지고 tracking을 이어나가야 한다. SORT는 어떤 방법으로 이를 가능케 했을까?
가장 핵심 알고리즘은 Kalman Filter와 Hungarian Algorithm이다. 이것부터 차근차근 알아보자.
- Kalman Filter
칼만 필터는 이전 시점의 상태에서 확률적 오차가 포함 되어 있고, 이전과 현재 상태에 선형적 관계가 있을 때 사용하는 알고리즘이다. 기존의 데이터에서 noise를 filtering하고 새로운 데이터를 예측하는 것이다.
주로 위키백과를 참고했다.
보통 선형 가우시안 분포 시스템에 사용되며, 비선형이거나 분포가 균일하지 않으면 variation된 알고리즘을 사용한다고 한다. 또한 MDP(Markov Decision Process)를 가정한다.
구체적으로 어떻게 예측하는 걸까? 우선 칼만 필터는 다음과 같은 시스템을 가정한다.
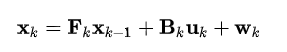
x_k는 k시간에서의 상태 벡터이고, u_k는 k시간에서 사용자 입력이다. F,B는 전이 행렬이며 w_k는 noise(다변량 정규 분포 가정, ~N(0, Q_k))이다. 이러한 시스템에서 예측값 z_k는

다음과 같이 구한다. H는 측정값 도출하는 행렬(대강 weight/parameter로 이해하면 될듯) v_k는 역시 noise이다.(다변량 정규 분포 가정, ~N(0, R_k))
마지막으로 초기 상태 x0와 noise(w_0~w_n, v_0~v_n)이 상호 독립이어야 한다. 이 조건이 만족될 때 칼만 필터를 사용할 수 있는데, 그 과정은 다음과 같다.
Prediction: 이전 상태에서 추정한 값에 사용자 입력이 들어간 후의 값을 예측하는 단계
수식으로는 다음과 같다. 다음 상태와 상태 공분산을 예측한다. 중간에 n|m은 m상태에서 예측한 n상태

Update: 위의 예측값과 실측정값을 비교해 수정하는 단계

구체적인 증명 등은 생략했다. EKF라고, 비선형 시스템이지만 미분 가능한 함수 개념을 도입하여 해를 찾는 알고리즘도 있다. 대신 최적의 해는 아님.
- SORT
다시 SORT로 돌아오면, 우선 초기 Object Detection에는 Faster R-CNN을 사용했다. 그렇게 찾은 object는 위의 칼만 필터를 이용하기 위한 상태 벡터로 표현되는데, 여기선 중앙 좌표와 scale, aspect ratio(종횡비)를 사용했다. 곧 x = [u,v,s,r,u_,v_,s_] 로 표현된다. _가 붙은 것은 velocity components로, 칼만 필터를 통해 최적화된다. (aspect ratio는 상수로 가정)
그래서 알고리즘의 과정은
1) 새 object검출 (by OD)
2) 다음 frame object 위치 예측 with 칼만 필터
3) 예측된 bbox와 실제 다음 frame 물체 위치의 IoU 거리를 계산하여, Hungarian algorithm을 통해 각 예측 box들을 실제 물체에 할당시킨다.
3-1) 이 때 최소 IoU보다 낮은 경우 제거한다. (중복 제거 등등의 이유)
3-2) 물론 낮은 데도 unmatched box가 있을 수 있기에, 기록해놓음. (이후 새 object tracker 생성)
4) match된 object, 새 object를 기록 (image에 그린다던지.등등)
5) 다음 frame 이동, 반복
의외로 간단함.
대신 칼만 필터의 행렬/공분산을 초기화하는 부분에 있어선 코드를 보면서 공부해야할 필요가 있을 것 같다.
- 부가설명
헝가리안 알고리즘은 할당 문제에서 최소 비용으로 할당하기 위해 나온 알고리즘이다.
https://gazelle-and-cs.tistory.com/29
우선 여기 예시로 설명이 잘되어 있으니 참고.
간단히 matching해야 할 두 집합에 대하여, cost 행렬이 주어졌을 때
1) 행,열마다 최소 값을 각 행,열에서 뺀다.
2) 두 집합이 Perfect Matching이 가능한지 확인 후, 가능하면 그 조합으로 matching한다.
3-1) 불가능하다면 0이 아닌 행,열에 대해 최소값을 0이 아닌 행,열에 대하여 다시 뺀다.
3-2) 뺀 만큼 0인 행,열에 더한다. 그리고 다시 Perfect Matching을 확인한다.
'내 맘대로 읽는 논문 리뷰 > CV' 카테고리의 다른 글
| Deep Learning for Person Re-identification:A Survey and Outlook (1) (0) | 2022.09.18 |
|---|---|
| Bayesian Learning (0) | 2021.05.03 |
| A Survey on Moving Object Detection & Tracking methods (0) | 2021.03.10 |
| Early-Learning Regularization : ELRloss (0) | 2021.03.10 |
| TResNet - ASLLoss (0) | 2021.03.10 |



