Wide & Deep Learning for recommendation systems
https://arxiv.org/pdf/1606.07792.pdf
본 논문은 작년 임베디드 수업 추천 시스템 프로젝트 때 읽은 논문으로, 복습하여 기록으로 남기고자 다시금 읽은 논문이다.
Intro
어떤 추천 시스템이든, 가장 기본적인 틀은 user,상황,아이템 등의 정보들로 이루어진 query에 대해 database 내 item들의 ranked list를 받아오는 것을 목적으로 하는 시스템이다. 여기서 ranking은 주로 아이템 연관성, 유저기반이면 뭐 클릭, 구매 내역 등의 연관성으로 랭킹을 매길 것이다.
추천 시스템의 중요한 challenge를 여기서 두 가지로 나눌 수 있는데, 하나는 Memorization으로, 기존 data를 통해 item 연관성을 배우는 것이며, 둘째는 Generalization으로 연관성을 통해 새로운 feature 조합 / feature를 찾는 것이다.
Wide & Deep 은 두 가지 챌린지를 서로다른 두가지 방법을 사용해, 합쳐 해결하고자 한 모델이다.
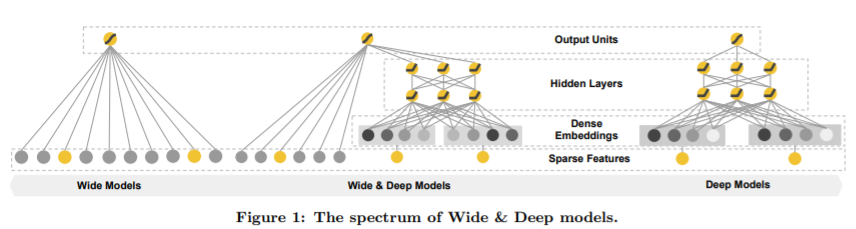
- Memorization
linear 모델을 사용한다. linear 모델은 여러 featrue간 cross-product를 사용하는데, 이는 적은 수의 parameter로도 모든 feature 조합을 기억할 수 있어 wide하고 sparse한 정보 기억이 효과적이어서 사용한다.
일반화에 쓰이는 DNN의 경우 sparse하고 high-rank의 정보를 배우기가 쉽지 않다. (어떠한 테크닉 없이, 단순한 Feed Forward network정도만 사용해서, over-generalization이 잦다. 그래서 narrow한 정보간 결합을 배우기 어려운 것.)
- Generalization
DNN(Deep neural network)를 사용한다. DNN의 경우 engineering burden이 적고, non-linear한 output을 뱉기때문에 나타나지 않았던 feature embedding에 대해서 연관성을 학습시킬 수 있다는 점에서 효과적이다.
linear모델의 경우 이미 존재하는 정보간 결합만을 계산하기 때문에, 새로운 정보에 대한 이야기를 학습 할 수 없다.
Implementation

Wide Component의 경우 간단히 y = (wT)x + b 와 같이, vector parameter로만 이루어진 linear model로 표현된다. 여기서 feature set x는 cross-product transformation을 사용한다. 간단히 AND(gender=남성,language='en')의 경우 남자 이며 영어를 써야만 1을 가지고, 하나라도 아니라면 0의 feature를 나타내는 것이다. 이를 통해 nonlinearity를 확보함과 동시에 feature간 interaction을 capture한다.
Deep Component의 경우 Feed Forward neural net으로, 위 그림의 오른쪽을 보면 구조를 알 수 있다. 우선 input은 language='en'과 같이 각 feature의 조합이다. 이들은 dense한 임베딩 벡터로 바뀐다.(임베딩도 trainable) 임베딩 벡터는 hidden layer들을 통해 계산된다. 흔히 생각하는 matrix parameter, bias, activation(ReLU)의 조합이다.
이 두 Component들은 prediction 시에 weighted sum(log odds)으로써 결합된다. 이를 joint training이라 하며, 앙상블과 달리 두 컴포넌트가 동시에 optimize된다. 저자들은 비교적 크기가 커야하는 앙상블 대신 같이 학습시켜 상호보완적 효과를 기대했다고 한다.
곧 로지스틱 회귀로써 최종 모델 output은

다음과 같이 계산한다. (합에 sigmoid)
Conclusion
지금까지 Wide & Deep 모델을 알아보았다. Google Play app 추천 시스템에 직접 사용되었다고 한다. 기존 Wide만, Deep방법만 따로 사용했던 모델보다 Online Acquisition Gain에서 1%가량의 향상을 보였다고 한다. 두 가지 방법을 통해 서로의 단점을 커버한다는 아이디어는 좋았던 것 같다. 실제로 CF(collaborative Filtering) 모델, content-based 모델보다도 좋은 성능을 보였고,
다만 역시 16년에 나온 모델이기에, 더 보충할 내용이 무지하게 많을 것이다. 단순한 정도론 여기선 단지 두 output을 더해 sigmoid를 통해 output을 냈다면, wide 와 deep output간의 비율(논문에선 weighted sum이랬는데, 그냥 더했더라)을 최적화할 수 있을 것이고, FFN보다 복잡한 모델을 사용할 수도 있을 것이다. 최근엔 BN이나 dropout을 통해 over-genralize문제도 좀 해결할 수 있을 것이니. 요즘은 Transformer를 사용하기도 하고.
아무튼 추천 시스템의 입문을 공부하기 좋은 논문.
'내 맘대로 읽는 논문 리뷰 > Recommendation' 카테고리의 다른 글
| Matrix Factorization (0) | 2021.04.05 |
|---|---|
| MEANTIME (0) | 2021.03.24 |
| BERT4Rec (0) | 2021.03.18 |
| SR-GNN (0) | 2021.03.10 |



