TuNAS: Can weight sharing outperform random architecture search?
https://arxiv.org/pdf/2008.06120.pdf
오늘은 작년에 나온 강화학습 기반 NAS논문, TuNAS를 분석해보도록 하겠다.
Introduction
이전 리뷰의 NAS에서는, 약 300대 가량의 GPU를 필요로 하였었다. 그래서 그 때도 말했지만 이제 효율성을 늘리기 위해 다음 세대들이 노력했다고 했었다. 실제로 이후에 나온 EfficientNAS, ProxylessNAS 등등의 주요 논문들은 weight sharing이라는 방법을 기반으로 efficient search method들을 개발하여 cost를 줄여왔다.
하지만 이 논문에선 이 weight sharing이 실제로 효과가 있는지, random search보다 정말 좋은지에 의문을 품고, 이를 실험으로 검증하는 동시에 새로운 novel 모델로 TuNAS를 제안한다.
미리 결과만 스포하자면, significantly하게 random search보다 efficient search method들이 어느 환경에서든 좋다는 것을 증명해냈다. 물론 weight sharing을 carefully하게 잘해야 한다. 또한 기존의 방법을 보완하여, 더 어렵고 큰 search space에서도 작동하도록 weight sharing 방법을 설계하였다고 한다.
Related work
- ENAS, ProxylessNAS등은 quality-latency tradeoff를 optimize하기 위해 weight sharing 방법에 기초한 search 방법을 사용했다. TuNAS 역시 같은 접근방법을 사용했으며 더 어렵고 큰 문제도 handle할 수 있도록 만들었다.
- NAS의 강점은 accuracy보다 많은 factor(latency, FLOPS, power consume 등등)에 대한 training이 가능하다는 것이다. (Multi-Objective search) TuNAS 역시 이러한 방법을 따왔다.
- CIFAR-10과 같은 작은 task들에 대해선 random search가 efficient search method들과 별 차이가 없었다는 연구결과가 있다. 이 논문에선 task크기를 키워 반박하고자 한다. (efficient search outperforms random search)
Search Spaces
TuNAS는 3가지의 Search space를 사용해 실험하였다.

Table 2부터보면, 첫 번째 space는 proxylessNAS에서의 것과 같은 search space를 사용하였다.
두 번째는 1번에서 두 가지 테크닉을 추가한다. 하나는 VGG의 idea를 참고하여, stride 가 2일때 마다 filter를 2 곱하여 크기를 유지해 주도록 하였고, 또 하나는 output filter size를 proxylessNAS에선 하나로 고정하였는데(보다 비싼 search 방법으로 미리 찾은 것이라 한다.), 정말 이 것이 좋은지 확인하기 위해 선택지를 늘린 것이다.
앞의 두 space는 MobileNetV2를 통해 만들어 졌다면, 마지막은 보다 큰 search space를 실험해보기 위해 MobileNetV3를 통해 만들어졌다. 또한 expansion ratio의 선택지도 늘리고, Inverted bottleneck layer에 SE의 유무를 선택지로 넣어, 정말 큰 space를 구현하였다.
이러한 space들에서 Ref model(여기선 MobileNet들), TuNAS, random search를 비교한 것이 Table 1이다. 앞에서 주장한 것과 같이, space가 커질 수록 random search와 searched model 간 격차가 벌어지는 것을 확인할 수 있다! 또한 Ref Model들보다 TuNAS가 더 좋은 성능을 보인 것도 확인 할 수 있다. (같은 latency time내에서)
TuNAS
그렇다면 TuNAS는 어떻게 만들어진 알고리즘일까? 앞서 말했듯 ProxylessNAS와 ENAS와 비슷하게 만들어진 알고리즘으로, 거기에 더해 robustness / scalability를 추가하였다고 한다.
TuNAS는 search를 통해 policy pi와 shared weight W를 학습한다. 쓰이는 RL method는 이전과 동일하게 REINFORCE를 사용한다. 구체적으로는 각 step마다 architecture a를 pi로부터 뽑아 shared weight를 통해 validation set의 한 batch를 통과시켜 quality Q(a), inference time T(a)를 얻는다. Q와 T의 조합으로 reward를 만들어 policy를 update 한 후 W를 training set batch로 update하면 step이 종료된다.
Weight sharing and cost reducing
Weight sharing을 좀 더 구체적으로 알아보면, 모든 network 조합 path에 대해 각기 다른 weight, parameter들을 두고, 어떤 path가 선택될 경우 그 path의 weight 결과를 통해 shared weight들을 update하는 알고리즘이다. 이는 적은 path 수에선 괜찮지만, 하나의 선택지만 늘어도 엄청난 cost를 요구하게 된다.

그래서 나온 알고리즘이 operation collapsing이다. Inverted bottleneck 구조의 경우 조합에 따라 252가지의 선택지가 생겨, 너무 많은 weight들을 들고 있게 되는데, 공통적인 1x1 conv 등에 대한 weight를 공유하게 하여 weight수를 줄이는 방법이다. ProxylessNAS의 경우 3x3, 5x5 depthwise kernel에 따라 1x1 conv도 다른 weight를 갖지만, operation collapsing을 사용하면 어떤 kernel을 선택하든 1x1 conv가 같은 weight을 갖게 한 것이다.
또 하나는 channel masking으로, input/output channel 수가 다르더라도 parameter수를 공유하도록 하였다. 가장 큰 수의 channel 크기 만큼 kernel을 만들어 두고, 작은 channel의 경우 앞의 N개만 사용한다는 식으로 사용한 것이다.(나머지 zeroing)
Reward function
연구진은 기존의 reward function으로는 제한된 시간 내에 best model을 찾는 것이 매우 어려워(retune이 필요한데, 이것이 실제 실험의 7배가 든다고 한다.) 새로 reward function을 정의하였다고 한다.
가장 처음에 나온 reward function은 다음과 같다.(soft exponential reward function)
Q,T는 각각 quality, inference time이고 T0는 target time이다. beta는 hyperparam이다. beta는 0보다 작기 때문에, 곧 quality가 가장 높으면서 inference가 작아야 best reward가 도출될 것이다.

하지만 만약 T가 T0보다 작아지면, beta의 값을 뒤바꿔야하게 된다.(적용 비율이 바뀌어 지기 때문, 1/x함수를 생각해보자!) 이 beta를 retune하는 것이 7배의 시간을 필요로 했던 것이다.
그래서 이를 완화하기 위해, T0보다 T가 작아질 경우 아예 reward에서 빼버리도록 바꾼 것이 다음과 같다.(hard exponential reward function)

하지만 이 때도 문제가 생기는데, target time보다 한참 작은 T에 대해 상대적으로 reward가 커져서 controller가 잘못된 선택을 하게 될 수 있다는 것이다. target만큼의 latency로 더 좋은 Q가 나올 수 있지만 덜 학습하여 더 낮은 Q가 나올 수도 있다는 이야기다.
그래서 TuNAS는 이러한 이전 function 대신 새로운 reward를 제시한다. 바로 절댓값을 이용하는 것.
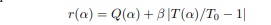
beta의 의미는 이제 얼마나 T가 T0에 가까워지길 원하는지를 나타내는 hyperparameter가 된다. (encourage) 해당 function의 경우 beta의 실제 값에 robust해지고, scale-invariance를 유지하기에 이전보다 좋은 함수라는 것이다.
****
이후 두가지 warmup이 나오고 구체적인 실험이 나오는데, 여기까지 읽고 난 후 아, 내가 논문을 잘못 골랐구나 생각했다. 너무 사소한 테크닉들의 결합이라... 마저 읽기 전에, 좀 더 앞의 논문을 읽기로 하였다. 사실 이해도 잘 되지 않았고...
이후 마저 리뷰