ProxylessNAS
https://arxiv.org/pdf/1812.00332.pdf
EfficientNAS 이후에 나온 더욱 효율적인 NAS를 위한 논문, ProxylessNAS다. TuNAS의 근간이 된 논문이기도 하며, 구체적으로 알아보자.
Introduction
NAS는 자동으로 효과적인 구조를 찾는 점에서 획기적이었으나, 그만큼의 엄청난 computational cost로 인해 거대한 task에 대해선 적용이 어려웠다. 이후에 나온 differentiable NAS 역시 memory consumption이 발목을 잡았다. 그래서 proxy라는 단위로 작게 학습하거나, 적게 학습하는 등의 방법으로 search를 하였는데, 이 논문에선 이것이 optimal하지 않기 때문에 직접적으로 구조를 학습할 수 있는 proxylessNAS를 제안하였다.
이를 위해 computational cost를 regular learning과 비슷하도록 줄여야 했는데, 이를 위해 여러 network를 두는 대신 one-shot model 하나에서 필요없는 path를 prune하는 방식을 택했다.
물론 이러한 방식은 memory에 영향을 준다. 그래서 architecture parameter를 binarize하여 오직 한 path만이 run-time마다 돌도록 하여 memory를 하나의 compact model을 학습하는 것 만큼으로 줄였다고 한다. 또한 non-differentiable한 latency를 학습할 수 있도록 연속 함수로 만들고, regularization loss로서 REINFORCE를 통해 학습할 수 있도록 했다.
간단히 정리하면
- 기존 NAS : network candidate 하나하나씩 뽑아 학습/비교하기에 computational cost 문제,
- DARTS 등 differentiable NAS : candidate 여러개를 통해 학습/비교 가능, 그러나 memory가 오히려 문제가 생김. (때문에 proxy라는 작은 task들을 돌려 학습)
- 이는 optimal 해가 도출이 되지 않았기에(증명 생략), proxy 없이 학습가능한 NAS를 만듬.
- Computational cost해결 위해 One-shot model 활용, 모든 path를 포함해 만든 over-parameterized network하나를 만듬
- 그래서 생긴 Memory 문제를 해결하기 위해 binarized parameter를 두어 한 path마다 학습, binarizing에 사용할 architecture paramter를 두어 학습함. 곧 redundant path를 찾아 prune하는 방식으로 search
- 또한 latency를 연속함수로 바꾸어 REINFORCE, gradient-based를 통해 학습 가능하게 바꿈.
이제 각 방법을 구체적으로 알아보자.
METHOD
Over-parameterized network
이제부터 우리의 신경망을 N(e1, ... , en)이라 하자. e는 각 신경망 edge라고 보면 된다. 그러면 이 edge들은 어떠한 operation oi가 될텐데(conv, pooling, identity 등등), 이러한 candidate operation의 집합 O가 있을 때, ProxylessNAS는 이러한 모든 candidate path를 반영하기 위해 mixed operation function mO를 정의하여, 각 edge마다 mO1(x) function을 할당한다. 실제 코드에선 nn.ModuleList 등을 통해 여러 모듈을 모아놓고, 이후 설명할 parameter를 통해 선택하는 방식을 쓴다.
ProxylessNAS에서 mO는 모든 operation output값의 합, DARTS에선 weighted sum(softmax)이었다.
직관적으로 알 수 있 듯, 이와 같이 모든 path를 반영하여 학습하려면 parameter 저장을 위한 memory가 path수에 비례하여 엄청나게 커질 것이다. 이를 해결하기 위해 binarized path를 상정하게 되는데..
<Binarized path>
그 방법은 다음과 같다. over-parameterized network를 학습할 때, 오직 한 path만 keep하는 것이다. 즉 binary gate g를 추가하여 mO가

다음과 같은 모양이 되도록 하는 것이다. 이렇게 되면 run time에서 유지해야할 memory가 하나의 path뿐이므로, 이전에 한 구조씩 학습했을 때와 memory 수가 같게 된다!
물론 어떤 path를 선택할지에 대한 parameter가 추가되게 되는데, (위의 p1~pN을 도출하는 parameter를 말한다) 이를 아래의 architecture parameter로 생각하면 된다.

그래서 weight parameter를 학습 할 때에는 path 선택확률을 동결하여 path를 sample하여 active된 path에 대해 weight를 update하고, architecture parameter를 학습할 때에는 weight를 동결시키고 architecture parameter를 update한다. 이렇게 학습 된 architecture parameter를 통해 낮은 확률의 path를 pruning하여 최종 path를 찾는 것이 핵심이다.
좀 더 구체적으로 architecture parameter 학습법을 보자.
BinaryConnect라는 2015년의 논문을 보면, real-valued weight를 binary gate의 gradient로 update하는데, 우리의 방법에서도 이를 적용할 수 있다.

real-valued weight인 a(architecture param)을 binary gate g로 approximate하여 표현한 것이다.(마지막은 softmax 미분값이다.) p는 위에서 본 p1~pN을 말하는 것이 맞다. 마지막 식에서 L에 대한 g의 미분값은 계산할 수 있기 때문에 a를 update할 수 있게 되는데, (순전파 때 g*o로 계산했기 때문에 o를 이용하면 된다.) 단순히 위 공식을 쓴다면 역전파 시 모든 o에 대한 parameter를 저장해야 한다.
순전파때와 비슷하게, 이를 위해 masking을 하게 되는데 N개의 path에 대해서 2개만 sampling하고 나머지는 masking을 해버리는 것이다. 없는 것처럼. N이 얼마가 되든, architecture update step마다 2개만 위 방법으로 update하도록 하여 memory를 saving한다! (하나는 improve, 하나는 안좋아 진다.)
Handle non-differentiable hardware metrics
이 장에선 latency와 같은 미분 불가능한 metric을 다루는 방법을 서술한다.
latencty를 미분가능하게 만들기 위해 연속 함수로 모델링을 시도하는데, 이를 위해 각 block i마다 latency의 평균 값을

로 모델링한다. p는 operation o를 선택할 확률, F(o)는 operation의 latency prediction model이다. prediction model은 실제로 총 latency 계산이 굉장히 느리고 비싸기 때문에, 1 pixel을 통해 latenct를 예측하는 model로 이해하면 될 것 같다. 이렇게 하면 E[latency]를 미분할 수 있게 된다. (예로 architecture update시, 미분값은 F(o)가 된다.
모든 네트워크에 대해서는 i block들의 E[latency]합을 사용하면 된다.
(prediction model에 대한 이해가 조금 부족하여, 코드를 참고할 예정..)

이 expected latency를 regularization loss와 비슷하게, scale factor와 함께 실제 loss에 포함시킨다. 위 그림을 보면 이해가 될 것이다.
이제 마지막으로 학습 방법을 보자. 우리의 목표는binarized parameter를 update하여, optimal binary gate g를 찾는 것이다. 이를 위해 policy gradient의 일종인 REINFORCE를 적용하여, 특정 reward R을 maximize하도록 학습시키는데, 다음과 같은 식을 통해 학습한다.

거의 처음 NAS에서 도출한 식과 똑같은 식이 나온다!

(NAS 식)
최종적으로, loss기반의 gradient-based update와 REINFORCE기반의 update를 통해 architecture parameter를 학습할 수 있다. (합쳐서 새로운 rule을 만들어도 ok)
Experiments
이전의 실험들은, 첫 CNN block을 작은 스케일로 학습한 뒤 transfer하여 큰 스케일로 stacking했는데, 이제는 그럴 필요 없이 바로 최종 task에 대해 search할 수 있다.
Search space의 경우 다른 논문을 backbone으로 변형했다고 하는데, 해당 논문을 따로 읽어볼 예정이다. 스킵
어쨌든, 첫 번째 실험은 CIFAR-10으로 CIFAR-10에서 5000개 정도를 val set으로 빼어 각각 Gradient, Reinforce 기반으로 학습하여 실험하였다. 총 648개의 decision이 있었다고 한다.
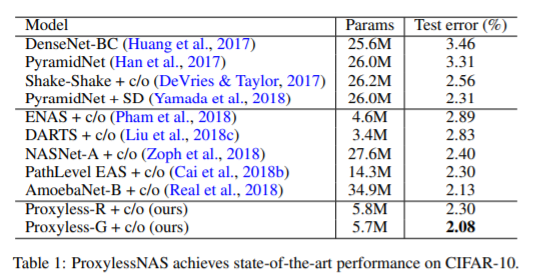
그 결과 gradient 기반 방법이 당시 가장 좋은 모델이었던 AmoebaNet-B보다 좋은 SOTA를 찍었다. 6배나 작은 parameter를 통해!
ImageNet에 대한 실험은 세 가지(Mobile,CPU,GPU)에서 진행했다고 하며, 여기선 latency가 중요한 objective기에 이를 고려하여 세팅을 했다고 한다. REINFORCE에서는 acc * [latency/T]^w를 사용했다. (이는 TuNAS에서 더 optimize된다.)


결과는 아주 좋았다. backbone으로 사용한 MobileNetV2보다 더 좋은 결과를 낳았다. (더 적은 cost로) GPU에서도 가장 적은 latency로가장 좋은 결과를 보였다.
흥미로운 결과는, 각 hardware마다 선호하는 model이 달랐다는 것이다. GPU의 경우 shallower, wider한 모델을 선호하였다. 그래서 large Inverted bottleneck 구조를 굉장히 선호했다. 반면 CPU의 경우 small Inverted bottleneck 구조를 선호하였다.아마 GPU가 더 높은 parrallelism을 가져서 해당 operation에 어드밴티지가 붙기 때문이다.
또한 모든 플랫폼에서 large Inverted bottleneck block을 downsample 이후 첫 블록에 선호하였는데, 아마 downsample 이후 정보 보존에 이점이 있기 때문으로 추측하고 있다.
Conclusion

ProxylessNAS는 path를 선택하는 parameter를 학습하는 방법으로 NAS효율을 굉장히 높이는 한편, latency를 학습시키고 weight을 한번에 학습하는 방법으로 SOTA 성능도 달성한 아주 놀라운 모델이었다.
또한 두 가지 학습 법을 사용한 것도 인상적이었다. 어떻게 조합할지 생각하는 것도 재미있을 것 같다.
아무튼, 앞으로 할 NAS 프로젝트에 좋은 지침이 된 것 같다. 다음으로 Search space를 탐구하기 위해 언급했던 논문을 읽을 예정이다.
'내 맘대로 읽는 논문 리뷰 > RL' 카테고리의 다른 글
| Neural Architecture Search with RL (0) | 2021.04.29 |
|---|
