AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss
https://arxiv.org/abs/1905.05879
코드: https://github.com/auspicious3000/autovc
Abstract
zero-shot voice conversion 기술로 2019년에 나온 논문. 해당 기술은 쉽게 말하면 A의 목소리(음색)으로 녹음된 발화를 다른 B의 목소리(음색)로 바꾸는 기술이다. 아래 데모 페이지를 참고하면 더 이해가 빠를 것이다.
https://auspicious3000.github.io/autovc-demo/
이러한 기술은 style transfer 기술이라고 칭하는데, 비슷한 approach들로 GAN, CVAE등의 generation model들이 있었으나 학습이 어렵거나, 좋은 결과를 내지 못하였다.
이번 논문에서는 이를 간단한(vanilla) autoencoder 하나와, bottleneck 구조의 모델을 통해 당시 SOTA모델인 AUTOVC를 제시했다.
Instruction
style transfer기술은 액션이나 sf 영화는 물론, 보안 등의 분야에 쓰이는 practical한 분야의 기술이다.
하지만 해당 분야 연구는 parallel (동일문장을 읽은 두명 데이터) data를 대부분 요구하고, zero-shot model(able to unseen speaker handling)이 존재하지 않았다.
이 논문의 AUTOVC는 간단한 구조의 autoencoder 모델을 통해, CVAE만큼 간단한 학습을 통해 GAN과 비슷한 성능을 내는 모델이다.
또한 parallel data를 필수로 하지 않고, (사람마다 다른 문장을 말해도 학습 가능) unseen speaker에 대해서도 decent한 성능을 냈다.
Problem Definition
어떻게 AUTOVC는 이것을 가능하게 했을까, 하나하나 따라가보자.
speech (앞으로는 X라 부른다)가 있을 때, 우리는 하나의 speech를 speaker identity와 content information으로 나눌 수 있다.
speaker identity (앞으로는 U라 부른다)란 음색과 같은, speech에서 speaker의 style을 나타내는 정보다.
content information (앞으로는 Z라 부른다)란 앞의 speaker identity 정보를 뺀, phonetic, prosodic 정보들이다.
곧 어떤 speech X는 p_X(·|U,Z)의 sample으로 생각할 수 있다.
그러면, 앞의 style transfer 문제는 이렇게 볼 수 있다.
"source speaker = A, target speaker = B일때 (U_A, Z_A, X_A), (U_B, Z_B, X_B) => (U_B, Z_A, ^X_A->B) 로 바꾸어라."
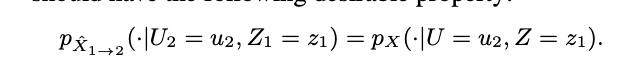
최종 목표는 위의 equation을 만족시키는 ideal converter를 찾는 것이 된다.
해당 문제는 A,B의 seen/unseen 여부에 따라 challenging 정도가 정해지게 된다.
Training scheme

AUTOVC는 크게 3가지 모듈로 구성 된다.
Autoencoder구조에 해당하는 encoder 부분을 Ec, decoder 부분을 D.
그리고 speaker identity를 encoding하는 Es.
Ec는 content를 인코딩한다는 의미에서 content encoder라고도 불린다.
1) Conversion
위 그림의 (a)에 해당한다. 우선 X_1을 Ec를 통해 인코딩하여 C_1 을 얻는다.
C_1은 X_1으로 부터 content information을 추출한 임베딩으로 생각하면 된다. (Z_1과 분포는 다르나 내포하는 의미는 같다.)
다른 하나의 X_2는 Es로 인코딩하여, S_2 를 얻는다.
그리고 C_1, S_2를 D로 디코딩하여 최종 X_1->2를 얻는다. (우선 그림대로 간단한 설명)
2) Training
위 그림의 (b)로, 학습에는 이전 모델들처럼 parallel data사용하는 것 대신 하나의 음성만으로만 학습하게 된다.
X_1을 Ec로 인코딩하여 C_1까진 동일하고,
Es로 인코딩하는 것도 X_1이 되어 S_1을 얻는 것이 달라진다.
이 C_1 과 S_1을 D로 디코딩하여 X_1->1을 얻는다.
이렇게 얻은 생성된 speech와, 원본 X를 비교하여 self-reconstruction loss를 통해 Ec와 D를 학습한다.
(Es는 pre-trained)
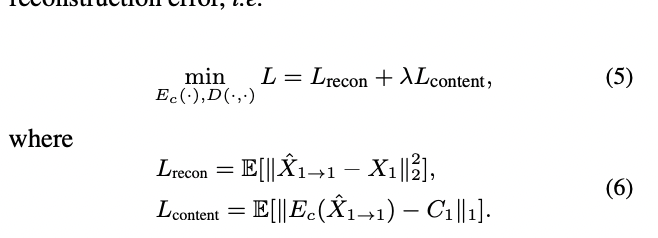
reconstruction loss외 하나는 content loss로, 생성 speech를 다시 Ec로 인코딩하여 나온 C와 원본의 C를 대조하는 loss다.
Validation
해당 학습에 대한 검증은 논문에 자세히 나와있으며, 조금 풀어보면
- Es는 U에 대한 일대일대응. (같은 U에 대해 같은 Es, 다른 U에 대해 다른 Es)
- T (speech array time)이 충분히 클 때(Markov process 조건 만족) 어떠한 적정한 C_1 dimension n을 설정하면, 모든 T에 대해서 ideal condition
의 수렴 조건을 만족시키는 위의 loss function을 사용할 수 있다. (세부 증명은 appendix로)
이는 곧 C_1의 dimension n, 즉 spekaer independent information을 충분히 인코딩할 수 있도록 n을 잘 설정하면 위 간단한 loss function으로도 학습이 가능하다는 이야기이다.

위 그림을 보자. C_1을 학습할 때, autoencoder는 X_1과 X_1->1을 같게 만들고 싶기에 C1을 이미 공급되는 S1정보 외의 정보들로 채우고 싶을 것이다.
그런데 (a)처럼 dim이 너무 크면, S_1외의 정보 뿐아니라 중복되는 정보가 더 들어 가게 된다.
그렇다고 (b)처럼 dim이 너무 작으면, C의 정보만으론 reconstruct하기 부족한 상황이 벌어질 수 있다.
즉 S1이 고정된 상태에서 X_1을 D가 reconstruct하기 위해선, C_1을 이용해야 하기에 C_1은 S_1정보를 제외한 X_1의 정보, 즉 처음에 의도했던 speaker independent information들만 가지도록 학습된다. 이를 위해서 C_1의 dimention 크기의 조절이 굉장히 중요해지게 되는 것이다.
그래서 ideal한 (c)의 상태가 되면, 다음의 두 가지 상태를 만족하게 되는데
(1) perfect X reconstruction
(2) C1 have only speaker independent informations, not contain any of U1 informations. ; speaker disentanglements
이 상태에 오면, 원래 목표였던 conversion도 ideal 상태임을 증명할 수 있게 된다.
(d) 참고해서 보면 이해가 쉽다.
동일 content를 가진 두 명의 음성이 있고, Ec에 넣은 음성이 무엇인지는 알 수 없다. 대신 Es에는 2번 음성이 들어간다.
이 경우 output으로는 2번의 음성이 나오게 될 것이다.
Ec에 넣은 음성이 1번일 경우, C_1은 (2)에 따라 U_1에 대한 정보가 없다. 따라서 C_1과 U_2를 합성한 output은 (1)에 따라 2번 음성으로 나올 것이다.
Ec에 넣은 음성이 2번일 경우 당연히 (1)에 따라 2번 음성으로 잘 나올 것이다.
이렇게 보면 결국 Ec에 어떤 음성을 넣든, ideal 조건에서는 두 개의 output은 같아야 한다. - 조건 1
그런데 여기서 reconstuction이 잘되는데 conversion이 안 된다고 가정을 하면, 두 개의 output은 다를 수 밖에 없다. - 조건 2
곧 여기서 조건간의 충돌이 있기 때문에, ideal 조건에서는 reconstruction이 잘 된다 => conversion이 잘 된다 와 같은 뜻이 되어야 한다. (contradiction 증명)
뭐 조금 길어졌는데, 결론은 reconstruction으로 학습해도 본 목적인 conversion을 잘하도록 학습하는 것과 같다는 뜻이다.
Architecture
세부 구조를 이제 체크해보자.

- Es : Speaker encoder (b)
Es는 앞의 증명 전제를 만족하기 위해, one-hot vector로 사용을 고려할 수 있다. 하지만 zero-shot model을 목표로 하기에, 다른 모델을 사용해 (GE2E loss 사용 모델) 3549명의 데이터로 pre-training한 Es를 사용했다. - Ec : Content encoder (a)
Ec는 speech (=melspectogram)을 input으로 받아, Conv 층 및 biLSTM 층으로 이루어진다. 적정 bottleneck dimension을 위해 downsampling 과정이 포함되며, 해당 downsampling은 정방향 및 역방향에 따라 다르게 데이터를 샘플링한다. - D : Decoder (c)
D는 앞의 C, 그리고 target S를 받아 새로운 melspectogram을 생성한다. 해당 과정은 upsampling을 포함한다.
Experiments
학습은 VCTK corpus로, test는 MTurk로 진행되며 MOS (mean opinion score) 및 similarity 점수로,
1) 타 모델과 비교 2) seen/unseen data에 대한 비교
로 진행되었다.
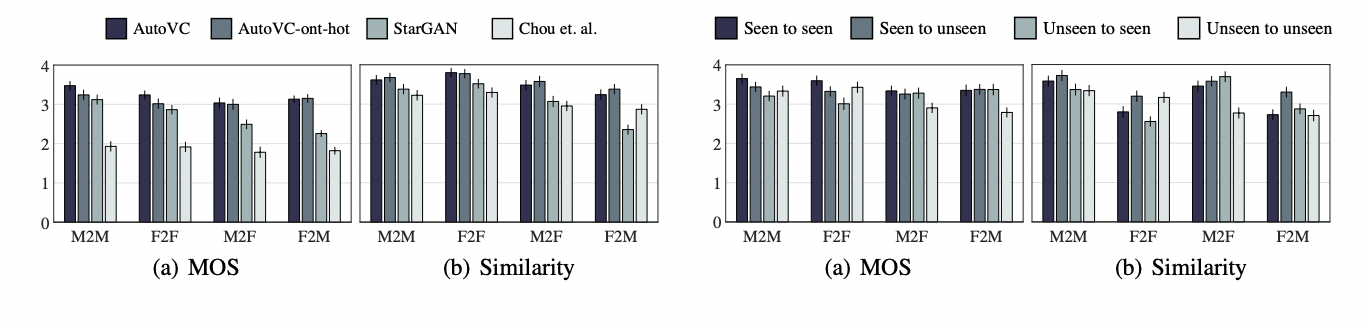
모델 간 비교에서는 fairness를 위해 모두 20명으로 학습했고, speaker embedding S의 영향을 보기 위해 one-hot으로도 학습했다.
그 결과 이전의 다른 모델과 비교해서 3이상의 점수를 보였고 (이는 parallel data 학습 모델보다 높진 않으나 (3.2~3.8), non-parallel 학습 모델 중에선 SOTA였다.)
또한 autoVC 와 autoVC-onehot에 큰 차이가 없어, S가 영향이 없다는 것도 확인할 수 있었다.
zero-shot compare는 autoVC에 한해 비교하였고, generalizability를 위해 20명을 늘린 40명으로 학습되었다.
그 결과, 40명으로 늘렸을 때 성적이 20명보다 더 좋았고, 심지어 unseen 테스트도 다른 모델보다 좋았다.
두번째 실험은 bottleneck dimension 관련 실험이다.
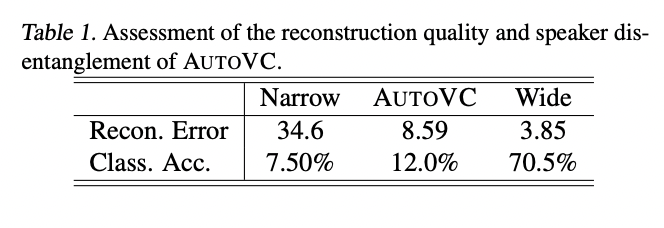
reconstuction error는 training set에 대한 l2-norm error (낮을 수록 reconstruction quality 높음)
class accuracy는 C 가지고 speaker classifier를 학습했을 때 정확도. (낮을 수록 speaker info가 C에 없음 의미)
각각 hparam은 (LSTM_dim, downsampling_factor) = (16,128) , (32, 32), (256, 8)
결국 적정한 두 지표를 가지도록 tuning 하는 것도 autoVC 모델 hparam search의 keypoint가 되는 것이다.
Conclusion
해당 논문은 non-parallel, zero-shot speech style transfer model에 간단한 autoencoder 및 loss function을 도입하여, 해당 분야에서 간단한 학습 방식으로 적은 데이터로 높은 성능을 낼 수 있게 했다.
다만 bottleneck tuning에 따라 성능이 많이 달라지게 되고, 이에 따라 완전하게 speaker information을 제거하기는 아직 모델 구조 상 완벽하진 않다고 보인다.
(위의 그림을 보면, Ec에 S_1이 들어가게 되는데, 해당 방식이 speaker information의 영향을 높일 수 있다 보았다. 물론 앞의 실험에서는 onehot과의 차이가 없는 것으로 나타났지만 speaker 수가 많아질 경우 balance를 맞추기 점점 어려워져, 결국 reconst error를 낮추기 위해선 speaker information이 추가적으로 들어가게 되어 conversion에 문제가 생겼다.)
물론 이는 실제 실험 및 결과로 부터 나온 짧은 결과라서, 명확한 통찰은 아닐 수 있다.; (의심점이라 보면 좋을 것 같다)
이 이후 같은 저자가 낸 speechsplit이라는 논문이 있는데, 다음에는 해당 논문을 추가로 리뷰해보겠다. 해당 논문에는 S_1을 붙이는 부분이 빠지고 구조가 많이 수정되어서, 확인을 해볼 예정이다.
'내 맘대로 읽는 논문 리뷰 > Speech & Signal' 카테고리의 다른 글
| X-vector (0) | 2022.08.10 |
|---|
