이번 lecture는 지난 L5와 이어지는 내용이기에, 같이 참조하면 좋다.
LSTMs
결국 지난 lecture에서, RNN은 vanishing gradient라는 큰 문제를 해결하지 못했다.
여기서 나온 아이디어로, 만약 hidden을 매번 다른 memory에 저장한다면 어떨까?
RNN은 hidden을 항상 덮어쓰기형식으로 진행하기에, 이전 time step의 hidden은 역전파시 무조건 다음 time step의 gradient의 영향을 받을 수 밖에 없다.
그렇기에 덮어쓰기가 아닌 새로운 hidden을 정의하여 학습할 수 있다면 괜찮지 않을까? 조금 더 구체적으론 계산하는 부분을 쪼개어 저장하는 part와 학습하는 part를 나눠보자는 말이다.
이는 LSTM이라는 모델로 진화하는 배경이 된다.
LSTMs은 Long Short Term Memory RNNs의 준말이다.
가장 핵심 아이디어는, 각 time step마다 (1) hidden state와 (2) cell state를 둔다.
여기서 cell state는 Long-term memory저장을 위한 storage로 이해하면 좋다.
cell의 정보는 LSTM이 읽고,쓰고,rewrite하는 등 자유롭게 접근할 수 있다.
어떠한 접근을 할지는 크게 3가지의 gate로 부터 정해지도록 한다.
한 time step에서 LSTM이 하는 일을 따라가보자.

3가지의 gate는 차례대로 forget, input, output gate라 불린다.
이들은 모두 자기만의 learnable parameter (W,U) 를 가지며 (각각 작은 classifier 하나라 보면 된다.)
이전 time hidden, 현재 time input을 받아와 sigmoid를 통해 0~1값을 얻어
어떠한 정보를 각각 잊을지/cell에 쓸지/cell에서 읽을지 를 정하도록 한다.
새로운 cell state가 될 후보 역시 비슷하게 cell의 learnable parameter (W,U)와 함께 계산되게 되며,
이전에 계산한 forget, input gate 값과 계산되어 최종 현재 time cell state를 계산한다.
최종적으로 output gate값을 계산하여 현재 time hidden state를 얻는다.
이 때 cell state, hidden state에 tanh function이 사용되는데, tanh는 -1~1로 수치를 조정하는 역할을 한다 보면 된다.
좀더 도식화하면 아래그림과 같다.

천천히 따라가다보면 계산 방식을 이해할 수 있을 것이다.
이러한 구조는 수많은 time step을 거쳐도 보다 정보 보존을 가능케 하여 vanishing gradient 문제를 완화하는 효과를 가진다. forget gate,input gate를 통해 cell state에서 필요한 정보파트를 모델이 저장하도록 학습할 수 있게 구조가 짜져있기에, 이렇게 학습한 모델은 긴 거리의 단어 사이 정보도 효과적으로 전달할 수 있게 한다.
물론. 계산이 복잡할 뿐 recurrent gradient 곱은 존재하기에 완전히 문제를 해결한 것은 아니다. (추후 다른 방법도 알아본다.) 뭐 이러한 문제는 굉장히 깊은 모델의 경우에도 RNN와 같이 존재하며, ResNet처럼 feed-forward를 통해 해결하려는 등의 시도도 존재한다.
More RNN Improvement : bidirectional/multi
- bidirectional RNN
이전 lecture에서 보았듯, RNN은 LM뿐아니라 문장 encoding에도 사용될 수 있다.
보통 최종 input에 대한 output state나, 모든 output state의 max/mean값으로 classifier를 훈련하여 사용하는 경우가 많다.
그런데 다시 생각해보면, 문장은 꼭 시계열적 시퀀스를 따르지는 않을 것이다. 즉 문장을 반대로 읽어가는 것이 이해가 쉬울 때도 있는 법이다. => 그렇다면 양방향으로 학습을 하는 것이 효과가 있지 않을까?

양방향으로 학습하는 경우, 각 학습의 weight는 따로 학습하되 hidden state는 둘을 concat함으로써 양방향의 context를 모두 가진 word embedding을 학습할 수 있게 한다.
이러한 방법은 대부분의 경우 단방향보다 좋은 성능을 낸다. (물론, LM에는 사용할 수 없는 방법이다)
entire sentence data 접근이 가능하다면 양방향을 써보는 것이 좋을 것이다.
- multi RNN
multi RNN은 간단하다. 위로 RNN을 여러개 쌓는것이다. 뭐 선형층 쌓는 것처럼 여러 RNN층을 쌓는 것,.

효과 역시 예상가능하듯 복잡한 표현을 배울 수 있다. 고로 성능도 대부분 좋음. (이후 trm, BERT에서도 여러개 쓴다.)
Neural Machine Translation
Machine Translation은 쉽게 말해 기계로 하는 번역이다.
기존 LM은 문장 하나하나의 데이터로 단어 하나하나의 확률을 잘구하도록 학습되었다면,
MT는 문장 pair 데이터를 통해 주어진 단어에 어떤 단어가 가장 잘 어울릴지를 학습한다.

위 그림과 같은 아이디어로, 최초의 MT는 통계적 방법을 이용하여 확률 분포와 모델링을 통해 해결하고자 하였다.
이제 NMT의 주된 모델 중 하나인 seq2seq 모델을 좀 더 알아보자.
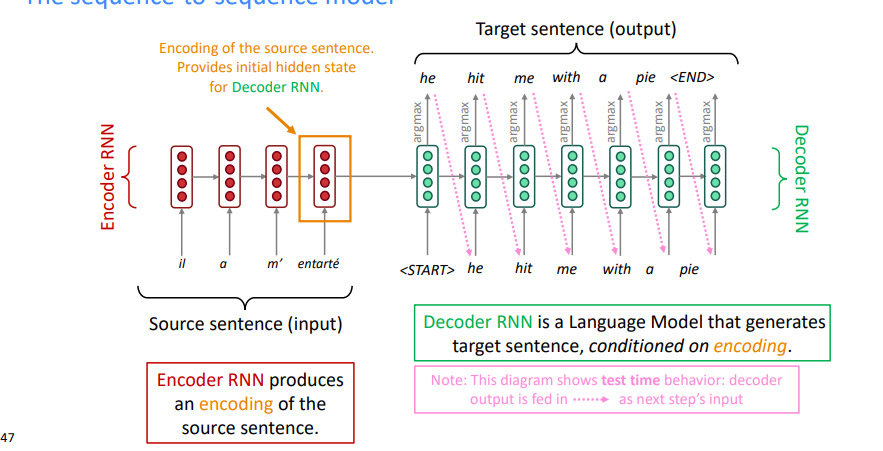
seq2seq은 크게 두 개의 RNN으로 구성된다.
앞의 encoder RNN은, 번역할 문장인 source sentence를 받아 각 word/sentence encoding을 얻는다.
여기서 나온 최종 output hidden은 source sentence의 hidden이라 보고, decoder의 첫 hidden으로 연결된다.
(앞에서 문장 encoding할 때 마지막 output state/hidden을 문장 encoding으로 학습하는 것과 어느정도 일치한다.)
뒤의 decoder RNN은 하나의 LM으로 학습됨으로써, 받은 hidden을 토대로 하나씩 알맞은(확률이 가장 높은) 단어들을 추출하여 번역된 문장인 target sentence를 뽑아낸다.
seq2seq은 MT외에도 요약, 대화(챗봇), 분류 등 여러 NLP task에 적용할 수 있다. encoder-decoder구조에 학습 label만 다르게 하면 대부분 이뤄진다. (이는 이후 trm, BERT에도 비슷한 구조가 쓰이고, 그렇기에 비슷한 task들에 모두 이용될수 있다.)
seq2seq의 학습은 decoder가 뽑아낸 output과 truth target sentence의 차이를 통해 CE Loss 합으로 진행되며, encoder에서 hidden을 decoder로 이어가기에 end-to-end학습으로 진행된다. (끊기는 부분없이 역전파 가능)
NMT의 평가는 BLEU (Bilingual Evaluation Understudy) 값으로 진행된다. 이는 인간이 직접 번역한 것과 비교하여 (n-gram씩 비교) 점수를 내는 것이다. 이 탓에 조금 부정확한 부분이 있을 수 있다. (좋은 번역이나 조금 다르면 점수 낮을수도)
이번 lecture는 이정도만 보겠다.
'모아 읽은 보따리 > cs224n' 카테고리의 다른 글
| L8: Transformers (1) | 2023.02.04 |
|---|---|
| L7: Attention (0) | 2023.02.04 |
| L5: Language Modeling, RNN (0) | 2023.02.02 |
| L4: Dependency Parsing (0) | 2023.02.01 |
| L3: Neural Nets (0) | 2023.01.31 |



