BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Introduction
BART는 seq2seq 모델을 pre-training하는 denoising autoencoder로, 지난 XLnet과 비슷하게 BERT(AE)와 GPT(AR)의 혼합된 모델이라 볼 수 있다.
BERT는 각 mask단어를 독립적으로 예측하기에 생성 task에 단점이, GPT의 경우 양방향 상호작용을 학습하기 어렵다. 따라서 이를 보완하기 위한 학습 방법을 상정한 것이다.
BART에서 가장 핵심적인 것은 학습 과정의 일반화로, BERT에서는 random masking된 단어들을 예측하도록 모델을 학습했었다면 이를 일반화하여, 학습 과정을
- input text에 arbitary한 noise를 준다.
- 모델이 이 text를 원본으로 복원하도록 학습시킨다.
로써 일반화시켰다. 그 후 noise주는 방법을 여럿 두어 모델을 학습하였다.
Model
BART의 모델은 이전 모델들을 대부분 차용하였다.

- Encoder는 bidirectional encoder, decoder는 autoregressive decoder이다. decoder각 층은 encoder의 마지막 hidden layer와 cross attention 계산을 추가로 하여 encoder의 계산 내용을 반영한다.
- 기존 모델들과의 차이는 encoder는 BERT와 달리 최종 FFN이 없고, decoder는 GPT와 달리 ReLU대신 GeLU를 사용하였다.
BART의 pre-training은 encoder에 훼손시킨 text를 넣고, decoder에 원본 text를 넣어 학습시킨다.
decoder의 최종 output과 원본 text간의 cross entropy로써 loss를 계산한다.
‘novel’ Transforms
이 논문에서 제시한 noise 방법들은 다음과 같다.

1) Token masking
BERT의 것과 같은 방식을 사용했다. random하게 masking하고 [mask]를 예측한다.
2) Token Deletion
임의 token을 삭제하고, 삭제된 token 위치를 찾아야 한다.
3) Text Infiling
포아송 분포(lambda = 3)으로 부터 span length를 뽑아, 그 만큼 text를 mask하고 각 mask 당 몇 개의 token이 없어졌는지 찾게 한다. 예시에선 BC가 mask되었고(2), D와 E사이 span length가 0으로 뽑혀 mask token이 추가되었다.
4) Sentence Permutation
문장 순서 교체.
5) Document Rotation
시작점을 하나 뽑아 그 점을 시작점으로 돌린다. 모델이 원본 시작점을 맞추게 학습시킨다.
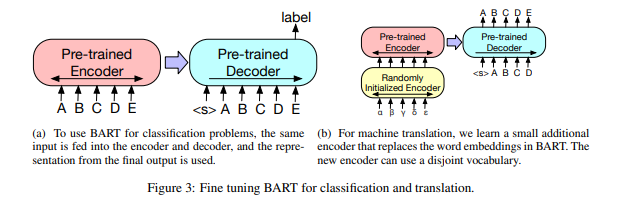
Fine-tuning
BART의 fine-tuning은 문제에 따라 다르다.
- 분류 문제의 경우 encoder, decoder 모두 원본 input을 넣어, 마지막 decoder output의 마지막 상태를 이용한다.
- 생성 문제의 경우 decoder가 autoregressive 모델이기에, direct하게 fine-tuning이 가능하다.
- 기계번역 문제의 경우 새로 encoder를 붙여 fine-tuning한다.
Experiments
1) Comparison of Pre-training transforms
noise 방식에따라 비교하였다. 각 6layer씩 설정한 base model이다.
Task는 QA, classification, abstractive QA, summarization, dialogue response, summarization 순이다

결과를 보고 저자는 다음과 같이 결과를 분석했다.
- 어떤 pre-training method가 모든 task에 대해 좋은 결과를 내진 못함.
- Token masking 방법은 분명 좋은 방법. Document Rotation/Sentence Shuffling 등이 저조한 성적을 보임
- BART 방식은 output이 input에 only loosely constrained하면 성능이 낮다. (PPL이 높은 task들, 연관 적음)
- text Infilling 방식이 가장 좋은 결과를 냄.
2) Experiment in large-scale model
보다 큰 batch로 학습하면 결과가 달라지기에, RoBERTa 모델과 같은 scale로 학습시킴.
- 12layer씩, 30% token을 masking함.
- 사용한 noise는 text infilling + sentence permutation

3) 기존 SQuAD, GLUE task 간 비교
- RoBERTa와 비슷한 성능을 냄. 이후 생성 task에서의 SOTA성능이 분류를 희생하여 얻은 것이 아니다

4) 생성 task 비교
- fine tuning에는 label smoothed cross entropy loss 사용
- CNN/DailyMail의 경우 첫 세 문장이 확률이 높은데, 성능이 제일 좋음.
- Xsum은 보다 추상적인 요약 task로, 성능이 굉장히 많이 오름.
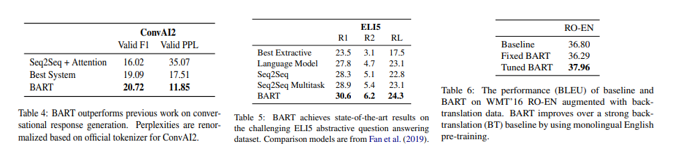
5) Conversation / abstractive QA / machine translation
- 대화 response 생성, QA 모두 가장 좋은 성능을 보임. 번역에도 좋은 성능.
- 허나 abstractive QA의 경우 question에 없는 정보는 잘 못 찾아 challenging
Conclusion
BART는 요약, dialogue 등의 task에서 큰 improvement를 보였고, 강점을 보였다. 그리고 어떤 noise 방법이든 시도해 볼 수 있게 하여, task에 맞게 noise 방법을 더 연구해 적용해 볼 수도 있겠다.
논문을 읽으며 든 생각들
- 우선 text infilling + sentence permutation 조합이 왜 성능이 제일 좋은지, 그리고 sentence permutation을 성능이 제일 좋았던 text infilling과 섞어 실험할 생각은 어떻게 하게 되었는지 궁금했다.
→ 요약 task에 해당 noise가 무슨 이유로 좋은 영향을 끼쳤는지 잘 모르겠다. 결과론적인건가? 논문에도 설명이 없었다.
→ 애초에 원래 방식인 token masking 등과도 엄청 큰 차이는 없었던 것 같은데, 살짝 논리가 부족하단 생각이 든다.
- model 설명이 조금 부족한 듯. 기존 꺼에서 대부분 가져다 쓰긴 했지만, 어떻게 아무 noise나 가져다 쓸 수 있게 했는지? 아니면 noise 방식을 어떤 방식으로 섞었는지 같은거.

위는 BART의 예시 해석문이다. (참고용)
'내 맘대로 읽는 논문 리뷰 > NLP' 카테고리의 다른 글
| Deeper Transformer with ADMIN (2) (0) | 2021.03.10 |
|---|---|
| Deeper Transformer with ADMIN (1) (0) | 2021.03.10 |
| MT-DNN (0) | 2021.03.10 |


