(1) Very Deep Transformers for Neural Machine Translation (ADMIN 사용, deeper 모델 학습 결과 위주)
https://arxiv.org/pdf/2008.07772v2.pdf
(2) Understanding the Difficulty of Training Transformers (ADMIN 이론적 배경, 구체적 이론)
https://arxiv.org/pdf/2004.08249.pdf
본 논문은 자연어 처리 공부 중 기계 번역 관련 면접 볼 일이 생겨 접하게 되었다.
그런데 아주 간단한 테크닉을 통해 학습 stability를 높여서, 모델 크기를 더 키울 수 있게 되어 결과적으로 좋은 모델을 얻을 수 있게 한 것이 신기하여 간단하게 적어 본다.
- background
기존의 transformer 모델은 base로 6개의 인코더, 6개의 디코더층을 사용한다. 그런데 기존의 방법대로 모델을 구현 시, 이 인코더/디코더 층이 많아지면 결과값이 발산(diverge)하게 되어, 쓰지 못하는 모델이 된다. (Vanishing Gradient)
Add & Norm 계층에서 Layer Norm이 그나마 이를 보완하긴 하나, 디코더와 인코더 하위 계층 간 gradient flow 부족이 가장 큰 문제로 알려져 있다. 그래서 pre-LN과 같이 먼저 LN한 입력을 더한 뒤 attn or ffn 네트워크를 지나게 하는 방법도 시도되기도 했다.
하지만 2번 논문에 의하면(같은 저자임) post-LN이 pre-LN보다 잠재적으론 더 좋은 결과를 낼 수 밖에 없다고 한다. (2번 논문 리뷰 참고) 그래서 post-LN을 쓰면서(즉, 모델 구조는 바꾸지 않으면서) gradient 문제를 잡기 위한 것이 ADMIN 모델 initialization 방법이다.
- ADMIN initialization
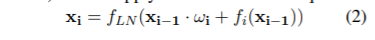
논문은 원래 transformer의 기본 계층 블록 구조(위에서 f_i는 attn층 혹은 ffn층이다.)의 수식에 w_i를 추가했다. w_i는 원래 input과 네트워크를 거친 input간의 magnitude unbalance를 고치기 위한 가중치라고 해석하면 된다.
2번 논문에 의하면 이 magnitude unbalance가 큰 영향을 끼친다고 한다.
그래서 ADMIN은 두 가지의 과정으로 나뉘는데,
-
Profiling 과정에선 w_i = 1로 두어, 기존과 같이 모델을 random하게 초기화하여 1step을 진행한다.진행하면서 각 층 residual network의 variance를 계산한다. ( Var(f(x_i-1)) )
-
Training 과정에선

다음과 같이 w_i를 두어 standard하게 역전파를 진행한다. 트레이닝이 끝나면 이 w_i가 모델 parameter에 folded back 되어 본래 transformer 구조를 만든다고 한다. (2번 논문 참고)
- Experiments
이렇게 학습할 경우, deep한 transformer도 diverge 문제가 해결이 되었다고 한다. 구체적 이론 배경은 2번 논문에서 보고, 여기선 결과에 집중해보자.

6L-6L은 각각 인코더 6층, 디코더 6층을 의미한다. 기존의 방법에선 60L-12L 모델이 diverge되어, 못 쓰는 모델이었지만, ADMIN으로 학습한 60L-12L모델은 diverge 되지 않았을 뿐더러 훨씬 좋은 결과를 내었다. 기존 모델의 BLEU score보다 2.5가 높았다.

Train perplexity를 보면, 기존 방식의 60L-12L 모델 학습은 gradient가 NaN이 되면서, PPL이 어느 정도 이하로 떨어지지 않는다. 이는 random 보다 못한 결과라 한다.
하지만 ADMIN을 사용한 모델은 확연히 PPL이 떨어지는 것을 볼 수 있으며, 이는 적은 layer를 사용한 모델보다 더 작아진다고 한다.
이러한 큰 NMT 모델의 발견은, 이후 noise가 많지만 큰 데이터를 취급하는 back-translation, adversarial training 등에 새로운 지평이 될거라며 저자는 말한다.
모델의 크기가 커지면, 분명 더 구체적인 (higher-level feature)feature를 뽑아낼 수 있을 것이고, knowledge distilation을 이용해 더 효과적인 모델을 만들어 낼 수 있을 것이다. divergence 문제를 비교적 간단한 수식으로 해결한 것에 대단히 신기하였고, 연구 지평을 넓혔다는 것에 큰 의의가 있는 논문인 것 같다. 이론적 배경은 (2)번 논문 리뷰로 가서 추가로 보도록 하겠다.
'내 맘대로 읽는 논문 리뷰 > NLP' 카테고리의 다른 글
| Deeper Transformer with ADMIN (2) (0) | 2021.03.10 |
|---|---|
| BART (0) | 2021.03.10 |
| MT-DNN (0) | 2021.03.10 |


