DG-STA
Dynamic Graphs for hand gesture recognition via Spatial-Temporal Attention
이 논문은 CV 팀 프로젝트에서 구현했던 논문이다. 그래서 논문 리뷰라기 보단 프로젝트 리뷰라고 생각하면 편하다. 실제로 프로젝트 얘기밖에 안한다. 논문 내용도 많지 않아서. 비교적 유명하진 않은 논문인데, 우선 이용한 이유를 말해보자면
우리의 프로젝트는 한국 수어 영상을 실제 단어,문장으로 바꾸는 모델을 만들자! 였다. 처음엔 영상을 frame 단위로 끊어, 영상의 얼굴, 손 point 들을 추출하는 모델 하나(1), point로 부터 gesture feature를 뽑아내는 모델 하나(2), feature를 통해 단어를 뽑아내 문장을 만드는 모델 하나(3). 총 세 가지 종류의 모델을 생각했었다.
그런데 막상 돌입하니 세 가지 모델을 하나하나 짜고, 학습하는것이 너무 어려웠다. 처음엔 (1)은 OD 모델 하나, (2)는 lucas-kanade와 같이 optical flow 활용, (3)은 transformer모델을 활용할 생각이었지만, 각 모델의 구현도 어려울 뿐더러 end-to-end로 만들자 하니 참고할 모델/논문이 부족했다.
그래서 부분적으로 합쳐진 모델을 찾았는데, 그것이 바로 이 논문이었다.! 손 point들로 부터 단어를 뽑아내는, 즉 (2),(3)모델을 합친 모델인 것이다. 그래서 우린 이 모델에 OD 모델을 적절히 합쳐 task-specific한 모델을 만들기로 했었다.
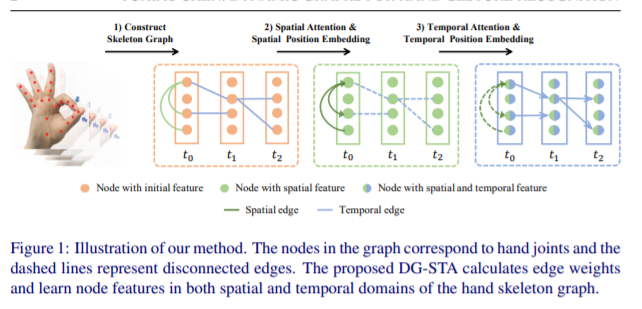
자, 다시 본론으로 돌아오면, 이 모델은 미리 구한 손 point들을 입력으로 넣어, skeleton graph를 생성한 뒤 두 번의 attention을 적용하여 손의 움직임을 학습하는 모델이라고 보면 된다.
input으로 B x T(time) x P(points) x 3(x,y,C)가 들어 간다. 여기에 Spatial Attention(point dim에 대한 attention)을 계산하여 더해주고 Temporal Attention(time dim에 대한 attention)을 계산하여 더해주어 최종 feature을 뱉는다.
이러한 Attention은 각각 동일 이미지 내 point간의 관계를 학습하기 위해, 다른 이미지 간 point간의 관계를 학습하기 위해 더해 진 것이다. 부가적인 네트워크 구조, 임베딩 과정은 아래를 참조하면 된다. 일단 주된 아이디어는 이것이니.

실제로 14개 정도의 적은 수의 단어에 대해서 좋은 성능을 보였다고 한다.

자, 그러면 이번 논문의 한계는 무엇일까? 일단 우리의 CV project는 만족할 만한 결과를 내지 못했었다. OD 모델 구현은 그럭저럭 되었으나 시간 상, 그리고 정확도 상의 문제로 openCV와 srhandNet이라는 다른 부가적인 pretrained network를 활용했었다.
*아래부터 개인 프로젝트 이야기.
우리 프로젝트의 문제는 꽤 많았는데, 일단 srhandNet에서 손 point를 해상도 문제인지, real time으로는 잘 못잡는 것을 알 수 있었다. 그래도 validation 과정에선 좋은 결과가 나와야 하는데, 이마저도 별로 였다. 즉 DG-STA모델에 결함이 있다는 것.
일단 데이터셋의 문제. 우리는 한국수어 영상을 AIhub 홈페이지에서 받아왔는데, 단어 수는 3000개이나 각각 5개, 그것도 같은 사람에 각도만 다른 영상이라 단어와 gesture를 연관짓기가 어려웠다. 단어 수를 한정함으로써 어느정도 성능을 올리긴 했으나, 논문과 같이 올리진 못했다. 당연한 것이 논문은 한 손만 쓰고, 14개 단어(제스처)에 대해 2800개의 영상으로 단어마다 200개 정도의 영상이 있어 학습이 우리의 데이터보다 잘되었을 것이다. 다양한 augmentation 방법을 통해 성능을 조금 극복하긴 했다. 그나마 우리 프로젝트에서 긍정적인 점.
또한 DG-STA는 이름이 거창하긴 하나, 결국 FC layer에 적절한 임베딩을 붙여 time/point dimention마다 multi-head attention을 한 번씩 계산한 모델이다. novel한 아이디어라기 보단 어찌보면 기존의 방법들을 적절히 덧붙인 방법이라고 볼 수 있겠다.
그럼에도 불구하고, 해당 모델에서 어느정도 variation을 주고, 단어를 한정하고 좋은 데이터셋을 썼다면 더 나은 프로젝트가 되지 않았을까.(모델 탓을 하면 안된다는 이야기) Transformer 모듈을 참고하여 attention 중간에 FFN sublayer를 덧붙인다든가, 아니면 encoder-decoder attention같이 한 attn 계산값과 input을 attention한다든지? 더 연구해볼 만한 주제인 것 같기도 하다. 우리가 사실 RetinaNet에 조금 삽을 푸느라 모델을 연구할 시간이 부족했다.
아무튼. 논문 리뷰라기 보단 프로젝트 리뷰가 되었는데, 결론은 gesture recognition에서 attention을, 그것도 두 가지의 attention 방법을 제시하여 좋은 성능의 모델을 만들어 낸, 그리고 새로운 지평을 열어 향후 연구 가치가 더 있다고 보는 논문이었다.
+더 찾아봤는데, sota모델들은 RNN,LSTM을 사용하더라, 아직 transformer mechanism이 novel하게 나오지 않았거나, 방법이 안 맞는 것일까? 시간이 나면 찾아보면 좋을 것 같다.
+TTM이라고 있긴하네. 다음에 읽어볼것
'내 맘대로 읽는 논문 리뷰 > CV' 카테고리의 다른 글
| SORT (0) | 2021.03.10 |
|---|---|
| A Survey on Moving Object Detection & Tracking methods (0) | 2021.03.10 |
| Early-Learning Regularization : ELRloss (0) | 2021.03.10 |
| TResNet - ASLLoss (0) | 2021.03.10 |
| RetinaNet (0) | 2021.03.10 |



