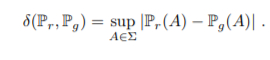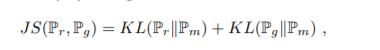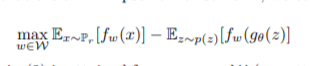오늘은 vanila GAN의 문제점들을 고친, Wasserstein GAN에 대해 분석해볼까 한다. 어려워서 따로 정리한 용어의 경우 [A*]로 적어 가장 아래에 정리해 두었다.
Introduction
Unsupervised Learning은 흔히 말해 데이터의 확률 분포를 학습하는 것이라고 한다. 이전의 접근에서는 이를 확률 밀도를 구하는 식(아래 그림-maximum likelihood) 으로 풀어서 Parameterized 확률 밀도들의 분포 P_θ를 원 분포에 최대한 가깝게 만드는 식으로 학습을 했었다. 즉 아래 식을 통해 구한 분포를 KL(P_θ | P_real)을 minimize하는 방식으로 학습한다.
하지만 이러한 방법은 low dimensional manifold 환경을[A1] 구축할 수 없어 (manifold를 모델링할 수 없는) KL divergence가 정의되기 어렵거나 발산하는 환경에는 적합하지 않을 것이다. 실제로 이런 환경이 흔하다.
그래서 모든 환경에서 KL divergence를 정의해주기 위해 가장 흔히 쓰이는 방법이 noise이다. noise를 모델 분포에 추가함으로써 모든 데이터를 포괄할 수 있게 만드는 것이다. (즉, 모든 데이터에 intersection이 생겨 KL divergence가 정의될 것이다.) 하지만 기존의 연구들이 말해 주듯 noise는 이미지의 퀄리티를 낮추고, blurry하게 만든다. 그래서 우리가 써온 maximum likelihood 접근법에는 noise가 필수적이나, 이것이 정답은 아닐 것이다.
그렇기에 최근에 나온 방법은 확률 밀도를 직접 계산하여 분포 P_θ를 구하는 것이 아니라, 하나의 fixed된 분포를 정해두고 parameterized function을 통과시켜 P_θ의 sample들을 직접 뽑아내게 하였다. 이러한 방법은 low dimensional manifold에 맞는 분포를 뽑을 수 있게 하며, 빠르게 sample을 뽑을 수 있는 데서 이점을 갖는다. VAE, GAN과 같이 유명한 생성 모델들이 이러한 방법을 사용함을 알고 있을 것이다.
그 중 GAN은 objective 선택이 능동적이나, 이제까지의 GAN의 경우 학습이 불안정하고 mode dropping[A2], G/D unbalance와 같은 여러 문제를 겪고 있다.
그래서 저자들은 이러한 GAN의 문제를 해결키 위해, 저자들은 P_θ와 P_real의 distance/divergence를 구하는 measure에 접근하게 된다. 여러 measure를 비교하는 것이 다음 장이다.
또한 parameter θ와 P_θ간 연속성이 중요함을 설명하며, 이는 분포간 거리 정의에 달려있다고 말한다. 다시 말해 θ가 최적으로 가면 P_θ도 최적으로 연속적으로 가야하기에, P_θ가 연속적으로 가도록 거리를 정의해야 한다는 이야기같다.
더불어 distance가 약할(?)수록 분포의 수렴이 쉬워 연속성을 정의하기 쉽다는 이야기도 하는데, 곧 topology가 약함을 이야기하는 것이다. 이 부분은 잘 모르는 부분이 있기에,, 적어두기만 하겠다.
Distances
여러 distance 정의들을 비교하며 새 distance를 제안하는 파트. 크게 4가지를 비교한다.
Total Variance(TV) distance
Pr(A)와 Pg(A)의 가장 큰 차이 값(상한)
Kullback-Leibler(KL) divergence
단, 앞에서 언급했듯 Pr,Pg는 동일한 measure u(defined inX)에서 밀도를 가지는 분포(=연속성)임을 가정.
Jenson-Shannon(JS) divergence
Pm은 (Pr + Pg) / 2 이며, 0과 1사이 값을 가지고 KL과 달리 Pm을 u로 삼으면 되기에 보다 robust함.
Earth-Mover(EM) distance / Wasserstein-1
저자들이 새로 제안한 것으로, Pr, Pg의 가능한 모든 joint distribution set에 대해 거리의 기댓값의 하한값을 찾는다. 이 식이 직관적으로 의미하는 바는 Pg에서 Pr로 transform하기 위해 필요한 mass량으로, 즉 optimal transform plan의 cost를 의미한다. 따라서 가장 최적의 cost가 적을 수록 Pr Pg가 비슷하다(거리가 짧다)로 해석할 수 있겠다.
그렇다면 정말 EM distance가 원래의 세 척도보다 이점이 있을까?
위 예시는 평행선을 학습할 때를 가정한 것으로, P0는 (0, Z), P_θ는 (θ, z)의 분포이다.
즉 좌표평면 상에서 x=0 평행선과 x=θ 평행선을 생각해보라. 그 선을 따라 점들이 분포해 있는 것이다.
그렇게 생각하고 계산해보면 위 그림과 같이 나오게 된다. ..간단히 W를 예로 들면 당연히 평행선 내 점들 사이 가장 짧은 거리는 선의 거리가 되고, θ가 되는 것이다.
KL/JS도 간단한 가정 및 계산을 통해 구할 수 있다! 우선 생략하고,
어쨌든 나오는 결론은, 다른 척도의 경우 θ가 0이냐 아니냐에 따라 값이 상수/무한대로 차이나는 반면 EM distance는 연속적으로 변한다는 것이다. 기존에 JS divergence를 썼다면, 처음에는 scratch이므로 log 2만큼 차이나다가 한순간 0으로 값이 변하기에, gradient가 불안정할 수 밖에 없을 것이다. KL divergence는... 여기까지.
이제 이를 GAN의 loss로 사용하기 위해, 연속성/미분가능성을 확인하는데, 엄밀한 증명은 논문을 참조하길 바란다. 논문 appendix C를 참조.
여기서 z는 latent variable, g는 z를 x로 바꾸는 generator이다. GAN을 다시 생각해보면 좋을 듯.
그래서 중요한 포인트는 g가 θ에 대해 연속이면 EM distance도 연속.
g가 립시츠 조건도 만족한다면 EM distance는 어디서든 연속하며, 대부분에서 미분가능. 이다.
립시츠 조건은 나도 잘 몰랐는데, 간단히 두 점 사이 거리가 일정 비율을 넘지 않는 것을 말한다. 아래 위키 백과 설명의 식을 보면 이해가 빠를 듯.
핵심은 다른 척도들의 경우 연속이거나, 미분가능하지 못하는 반면 EM distance의 경우 조건만 맞춰주면 안정적인 loss로 활용이 가능하다는 것이다.
WGAN
이제 EM distance를 통해 GAN을 학습하면!! 되는데,, 앞의 EM distance의 정의를 보면, Pr을 알아야 계산이 가능함을 쉽게 알 수 있을 것이다. 따라서 Kantorovich-Rubinstein duality라는 것을 통해 식을 변형하여
와 같이 만들 수 있다고 한다. 이는 1-립시츠 조건을 만족하는 f에 대한 정의이다.
우리의 f는 parameterized된 함수기에, fw로써 식을 변형하면 (이 경우에도 각 fw는 k-립시츠 조건을 만족해야 함)
로써 바뀐다.
최종적으로는 다음과 같으며, 앞의 Pr을 사용하는 부분도 역전파시엔 미분되어 없어진다.
다른 parameter w 역시 같은 식을 사용해 역전파되며, 간단히 두 칸 위의 식을 θ가 아닌 w로 미분하면 된다. 아마 vanila GAN과 식이 거의 비슷해져서, 이해가 쉬울 것이다.
그렇다면 fw는 어떻게 정의할 수 있을까. 러프하게는 신경망을 생각할 수 있을 것인데, 앞에서 언급했듯 우리의 f는 반드시 k-립시츠 조건을 만족해야만 loss가 미분가능해진다. 따라서 저자들은 각 gradient update이후 clamping을 해줌으로써, parameter를 일정 비율 내에서 맞추게 하였다.
물론 weight clipping은 clipping 값을 적절히 맞추지 않으면 학습이 느려지거나(big clip) gradient vanishing(small clip)을 유발할 수 있어 좋은 방법은 아니라고 언급한다. 그래서 차후로 넘기게 되니 skip. (WGAN-GP)
다음은 WGAN의 학습 알고리즘도로, 일반적인 GAN의 학습 루틴과 거진 비슷하다.
한번 보면, 먼저 critic은 기존 GAN의 discriminator역할을 한다고 보면 된다. critic의 parameter w 역시 EM distance를 통해 학습하게 된다. 그래서 먼저 n_critic만큼 critic parameter를 학습하고, (clipping포함) generator의 parameter θ를 앞의 Theorem 3의 식을 통해 학습한다.
여기까지 보면 WGAN에 대한 기본적인 이야기는 모두 한 것 같다.
Empirical Results
WGAN이 정말로 수렴성, 학습 안정성 문제를 해결했는지 결과를 통해 알아보자.
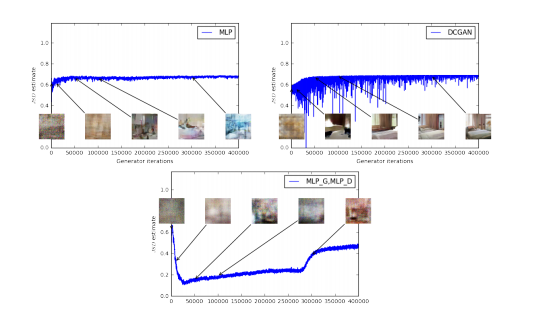
먼저 볼 것은 JS distance를 사용한 것으로, generator의 차이에 따라 성능에 차이가 있으나 모두 loss가 증가하는 모습을 보인다. 생성되는 그림도 DCGAN generator 외에는 알아보기 어렵다.
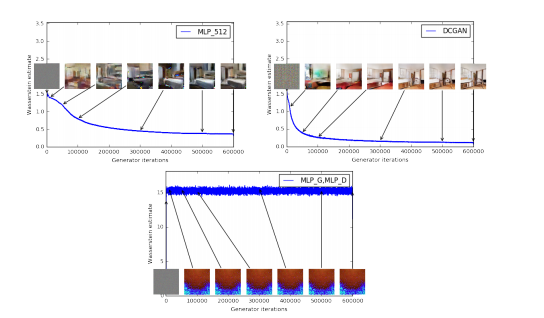
이 것이 EM distance를 사용한 WGAN으로, loss가 수렴하며 그림도 점차 명확해짐을 볼 수 있다. 다만 generator와 critic을 모두 MLP로 사용했을 때는 loss가 떨어지지 않는 것으로 학습에 실패도 하는 모습이다.
이와 함께 non-stationary한 문제임을 말하며, momentum이 포함된 adam과 같은 optimizer는 문제를 일으킬 수 있기에 RMSProp을 사용했다고 한다.
결론적으로 WGAN은 GAN의 문제였던 학습 불안정성, loss 발산, mode collapsing(적진 않았지만 논문에서는 한번도 보지 못했다고 말한다.), G/D unbalance 문제등을 distance를 바꿔줌으로써 해결할 수 있었다. 다만 clipping과 같이 해결해야할 문제도 물론 남아있다.
개인적으로는 기존에 GAN의 아이디어 하나는 정말 좋다 생각했는데, 문제가 많다고 알려져 쓰기가 어렵다 라고 생각하고 있었다. 물론 학교 수업에서 한번 들은게 전부였으니.... 어찌 되었든 제대로 공부를 해보니 많은 improvement가 있었고 실용화될 수 있다는 생각이 든다. 단지 이게 17년 논문이니 아직 갈길이 멀어보인다는 것..? 천천히 공부를 많이 해야하는 분야로 느껴진다.
Appendix
[A1] low dimensional manifold
low dimensional manifold 는 어디서 찾은 설명을 인용하자면, 침대보(2D)의 무늬가 접기 전엔 잘보이고, 예측이 쉬웠는데 침대보를 접어 공모양으로 만들면(3D) 무늬를 인식하기 어려울 것이다. 이렇게 데이터를 인식하기 쉬운(figure out manifold) 환경을 low dimensional manifold라 하며 이러한 환경일 때 우리(혹은 머신)가 데이터의 패턴을 잘 인식하고 모델링이 쉬울 것이다.
mode는 통계학에서 최빈값으로, mode dropping / mode collapsing은 multi-modal 데이터셋에서 일어나게 된다. GAN의 generator와 discriminator는 서로를 번갈아 학습하게 되는데, 만약 서로 잘못된 부분을 학습하게 된다면 둘 다 학습되지 못하고 진동하게 된다.
이 상태에서 원래 0번째 mode를 생성해야 하는 분포가 1번째 mode로 옮겨져 학습되면, 생성자는 1번째 mode만 계속 생성하게 된다. 즉 생성하는 결과가 동일해진다는 것이다.
예로 MNIST의 경우 0~9까지의 숫자를 균등하게 생성해야하지만, mode dropping이 일어날 경우 1과 같이 한 개의 숫자만 계속 생성하게 학습된다는 것이다.
이는 분명 이상한 현상이지만, GAN의 학습 objective에선 generator는 real data와 비슷하니 문제없고, discriminator 역시 문제를 모를 수 밖에 없다.