http://proceedings.mlr.press/v97/geifman19a/geifman19a.pdf
논문
https://github.com/HyunsuKim6/SelectiveNet-Pytorch
GitHub - HyunsuKim6/SelectiveNet-Pytorch: Pytorch implementation of SelectiveNet https://arxiv.org/abs/1901.09192
Pytorch implementation of SelectiveNet https://arxiv.org/abs/1901.09192 - GitHub - HyunsuKim6/SelectiveNet-Pytorch: Pytorch implementation of SelectiveNet https://arxiv.org/abs/1901.09192
github.com
코드
SelectiveNet: A Deep Neural Network with an Integrated Reject Option
selective prediction (= reject option) 문제 해결을 위한 deep neural network architecture
기존 해결방법 : threshold over the prediction confidence. => 일정 수준 이상의 확률치가 못될 경우 prediction을 회피.
SelectiveNet은 classification(or reg), rejection을 동시에 end-to-end로 가능하게 학습되며, 이러한 방식이 여러 well-known dataset에서 risk를 커버했다는 결과가 나왔다.
- Introduction
통계적 불확실성을 잡는 것은 딥러닝에서 정말 중요한 부분이다. 자율주행, 의료계와 같은 task들에서는 조금이라도 비껴가면 굉장히 큰 문제로 바뀌기 때문에, 특히나 중요할 것이다.
기존에는 이를 위해 일정 임계치를 pretrained model로부터 얻어, 그 임계치에 도달하지 못하는 경우 prediction을 보류하는 방식을 썼다. 이 경우 첫번째 학습 때 결국 모든 데이터를 보고 threshold 수치를 정해야 하고, 이는 곧 불필요한 학습을 한 번 필요로 한다는 뜻이 된다.
Selectivenet은 실제 학습과 rejection 학습을 동시에 할 수 있게 하기 위한 구조로, 주요 특징 사항은:
- selective loss function : optimize a specified coverage slice using a variant of the interior point optimization method
- selective network : A three-headed network for end-to-end learning
- selective net for regression : providing the first alternative to costly methods such as MC-dropout, ensemble
우선 나도 selective function에 대한 이해가 잘 되지 않아, 바로 2번 장으로 넘어가면 problem definition 장이 있다.

쉽게 말해 selection function g에 따라 결과 값을 내냐, 안내냐를 선택한다는 것. 이 g는 확률적일수도, determimistic할 수도 있음.
selective model g의 평가는 coverage, risk로 결정되는데,

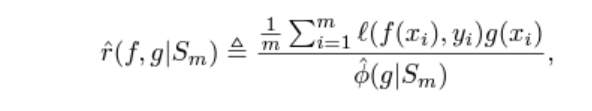
둘은 상충하는 관계로, 주로 risk-coverage graph를 통해 이를 나타낸다.
selective model은 곧 risk에 대해 coverage를 최적화하거나, 반대로 coverage를 고정하고 risk를 최적화하는 형태로 학습된다.
본 논문에선 우선 후자의 경우, 주어진 coverage에서 risk를 최적화하는 문제를 생각한다.
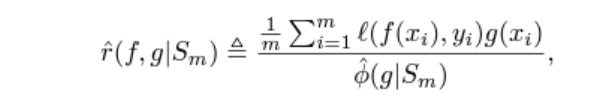
이전에 나온 테크닉들 중 하나는 MC-dropout으로, monte carlo 방법을 생각하면 된다. 즉 수많은 feed-forward과정에서 통계적으로 prediction threshold를 estimate하는 것이다. single network로 가능한 방법이지만, 그만큼 cost가 굉장히 크다,.
- SelectiveNet
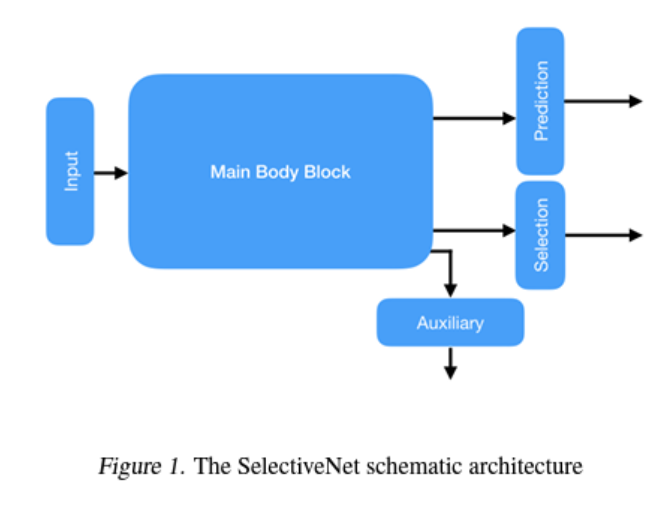
큰 그림은 다음과 같다. 쉽게 보면 input에서 main body로 가면, output이 3가지로 나뉘게 된다.
prediction은 f(x), selection은 g(x)이고 auxiliary head는 h(x)로 표현되는데, 이는 main body의 relevant feature construction을 강화하기 위함이라고 한다. (나중에 구체적으로)
inference는 간단한데, g(x) > 0.5일 때 prediction값을 내뱉고, 아니면 생략한다.
그러면 어떻게 해당 network를 optimize할까.
앞에서 보았던 objective는 다음과 같다.
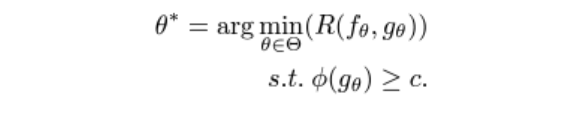
주어진 coverage constraint에서 risk를 최소화하는 것. 여기서 coverage constraint를 enforce하기 위해, Interior Point Method (IPM)이라는 방법을 응용했다고 한다. 곧 다음과 같은 unconstrained objective를 얻게 된다.
IPM: https://wikidocs.net/21306, wiki백과 참고
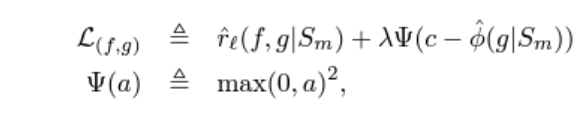
Sm은 sample 집합이라 보면 된다. c는 target coverage, lambda는 조절을 위한 hyperparam이다.
쉽게 보면 결국 risk를 최소화하는 동시에, coverge를 target coverage에 가깝게 만드는 최적점을 찾는 loss 함수인 것.
둘을 조절하는것이 lambda라 보면 된다. lambda는 뒤에 실험 결과에서 최적을 찾게 된다.
그리고 여기서 auxiliary head의 쓰임이 나오는데, 위 loss만 사용하면 main body에 대한 주 학습이 잘 안 될 수 있다. 따라서 원래의 loss 함수(MSE, CE등)를 통해 학습하도록 한다. 즉 coverage-invariant하게 학습하는 head를 통해 main body 학습을 강화한다는 것이다. 물론 이 head는 실제로 사용은 하지않고, train시에만 쓰인다.
이 head는 f(x)와 같은 task 형식으로 학습된다.
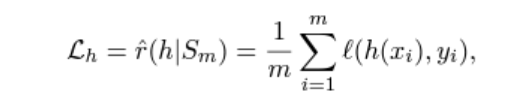
만약 auxilary head없이 학습할 경우, 네트워크는 target coverage c에 집중하기 때문에 곧 low level feature학습이 상대적으로 우선순위가 떨어지게 된다. 그렇게 되면 네트워크가 wrong subset에 overfit될 수 있는 것이다. 그래서 위 둘 함수를 적절히 조율하여 최종 loss를 만든다. 논문에서는 a=0.5로 학습했다고 한다. (별도 tune과정 x)
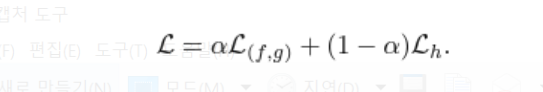
'내 맘대로 읽는 논문 리뷰 > 기타 분야' 카테고리의 다른 글
| WGAN-GP (0) | 2021.08.02 |
|---|---|
| Wasserstein GAN (0) | 2021.07.29 |
| A novel wavelet sequence based on deep bidirectional LSTM network model for ECG signal classification (0) | 2021.07.14 |


