https://arxiv.org/pdf/1704.00028.pdf
오늘은 지난 WGAN에 이어, WGAN의 문제를 보완하여 현재까지도 쓰이는 WGAN-GP를 읽어보기로 한다.
Introduction
지난 WGAN 리뷰에서 보았 듯이, WGAN은 그동안 GAN에서 써왔던 KL divergence등의 metric들의 발산성, 불연속성등의 문제를 해결하기 위해 새로운 loss function인 EM distance를 제안했다. 부드럽게 수렴하며, 립시츠 조건만 만족하면 연속/미분가능성을 보장함을 증명하여, 이를 통해 mode collapsing과 발산 문제를 해결할 수 있었다.
다만 지난 리뷰에서 보았듯이, WGAN에서는 이 립시츠 조건을 위하여 조금 non-formal한 방법인 clipping을 사용, discriminator(critic) 학습 때마다 weight을 인위적으로 clipping시켜 범위를 맞추었다. 이는 분명 좋은 방법이 아니고, 더 나은 방법이 있을 것이라 하였는데,,,
그것이 바로 이 논문에서 나온 gradient penalty방법이다. 미리 간단히 스포하면, discriminator loss에 gradient norm을 페널티로 추가하는 것이다.
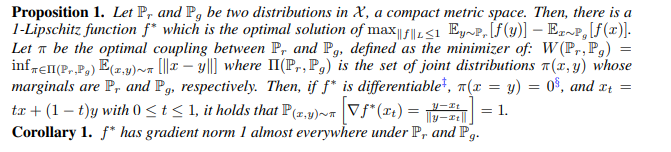
저자들은 핵심이 되는 이 정리로부터 페널티를 부여하게 된 배경을 설명한다. 매우 복잡한데, 간단히 보면 WGAN의 두 분포 Pr, Pg와 기존 critic loss에서 optimal 해 1-립시츠 함수 f*에 대해서, 찾아낸 EM distance의 optimal coupling을 pi라 하면 다음이 성립한다고 한다.
f*이 미분가능이고, pi(x = y) = 0면 x,y 사이의 모든 interpolation들에 대한
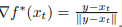
이 1이 된다는 것이다. 곧 우리는 fw를 통해 줄곧 optimal f*을 근사해왔는데, (신경망을 통해서) 지금 알아낸 f*의 특성을 fw를 맞춰주면 fw가 보다 쉽게 f*에 근사할 수 있게 되고, WGAN에서의 조건도 clipping없이 맞춰 줄 수 있게 되는 것이다..!
보다 명확한 증명은 논문에 있다.
Weight clipping의 문제
위의 조건을 맞춰주기 전에, weight clipping의 문제를 알아보자. 우선 실험적으로 보아도, BN을 사용해도 학습이 안될 때가 존재했으며, 발산하는 경우가 잦았다.
보다 구체적인 이유들은 여러가지가 있는데, 첫째는 weight clipping은 자칫 network를 simple한 함수로 critic를 유도하게 된다. 논문에선 이를 capacity underuse라는 말로 설명한다. 위의 Corollary 1번을 보면, Pr, Pg아래서 optimal f*은 거의 모든 곳에서 1의 gradient norm을 가진다고 되어 있는데, weight clipping을 쓰면 maximum gradient norm k로 수렴하려 하게 되고 이것이 simple function을 유도하게 된다고 한다.

왼쪽 예시를 보면, 위쪽이 clipping을 사용한 것, 아래가 penalty를 사용한 것인데 위쪽 함수가 확연히 간단한 구조를 띄고 있음을 알 수 있다. 이러한 간단한 구조는 점들의 분포를 반영하기 어렵고, 더 어려운 분포일 수록 문제가 심해진다.
오른쪽 예시를 보면 weight clipping을 쓴 경우 gradient norm이 1로 수렴하지 않고 발산하는 것을 볼 수 있다. (정확히는 어떤 수로 수렴하려 할 듯) 이렇게 학습이 될 경우 오른쪽 예시의 오른쪽 위 그림처럼 weight의 분포가 굉장히 불균일해지게 된다. 대신 penalty 방법을 쓸 경우 오른쪽 아래와 같이 weight 분포가 학습된다.
이 단락을 간단히 요약하면, weight clipping은 gradient norm을 1이 아닌 maximum gradient norm으로 수렴하도록 하여, 보다 간단한 함수를 학습하게 하며 weight 분포를 불균일하게 만든다. 이러한 현상들이 gradient vanishing등의 문제를 일으킨 것이다.
Gradient Penalty
본격적으로 GP에 대해 알아보자. 앞에서 말한 1-립시츠 조건을 만족해주기 위해, gradient norm을 1로 맞춰주는 것을 목표로 하는 것이라 보면 된다.

이제 뒤의 penalty식이 보다 직관적일 것이다. penalty에서 쓰는 x_hat의 분포는 Pg와 Pr의 interpolation에서 random하게 sampling하여 사용한다. 즉 penalty를 통해 Pg와 Pr 사이 interpolation 분포의 critic gradient norm을 1에 근접하도록 학습하게 된다.
Experiments
실제로 아주 다양한 실험조건, 특히 최악의 조건을 가정하고 학습시켰음에도 그렇다할 결과를 낸 것이 penalty의 위력을 실감하게 한다..!

곧 batch normalization이 없어도, MLP만 사용하더라도, 대용량 이미지 모델에서도 잘 수렴함을 볼 수 있다.
이번 논문은 비교적 간단해보이지만, 결국 저 proposition 하나로부터 모든 이야기들이 나왔다고 해도 과언이 아니다. 곧 저런 proposition하나를 이끌어내는데 정말 많은 연구가 필요했을 것이다.
어쩌면 수학의 중요성을 또 다시 느끼게 되는 한편 증명 파트를 차근히 읽어봐야 겠단 생각이 든다. 결국 이러한 지식, 증명 과정 하나하나가 모여 새로운 지식, 혹은 실마리가 될 수 있으니..!
다음 리뷰는 오랜만에 자연어처리 쪽을 파헤쳐 볼듯하다.
'내 맘대로 읽는 논문 리뷰 > 기타 분야' 카테고리의 다른 글
| Selective Learning: SelectiveNet (0) | 2022.01.05 |
|---|---|
| Wasserstein GAN (0) | 2021.07.29 |
| A novel wavelet sequence based on deep bidirectional LSTM network model for ECG signal classification (0) | 2021.07.14 |


